Overview
This project is an implementation of the Monte Carlo Tree Search (MCTS) algorithm, intended for use in human vs AI games. MCTS builds a search tree by running simulations and aggregating results, using these results to choose and optimal action. In the context of games the algorithm explores all possible moves from a current state by simulating random action choices against a game engine until an end state is reached. Over the course of many of these simulations it builds a statistical model of the decision space, which is used to select the best action.
Design
MCTS uses four distinct phases during its playout process, these are repeated until an arbitration decision metric is reached. The playout process starts fresh for every new move to properly account for the changed state of the game.
Selection: Starting from the root node, the search tree is descended until a leaf node with possible moves is reached. The path taken depends on a formula (UCT in my case) that balances exploration vs exploitation, e.g. whether to explore untested paths or gather more data on tested paths.
Expansion: After reaching a leaf node new child nodes are created, one for each possible move from this game state. One of these nodes is chosen for simulation.
Simulation: The game is simulated until completed using random (or heuristically influenced) moves.
Backpropagation: The result of this playout is used to update itself and parent nodes. Each node tracks both the number of times it has been visited, and the number of times one of those visits has resulted in a positive outcome.
When calculations are stopped the gathered data is used to determine the most favorable move. The design of the search tree and backpropagation means this choice will take future scenarios into account.
I designed the algorithm’s implementation to be modular. It can be given any game engine that meets the interface requirements, and does not need modification to match actual game mechanics. This is achievable as the MCTS algorithm only evaluates actions and end results in its simulations, it does not make heuristic decisions based on game state. That being said, I have included a heuristic hook which can be used to optimize calculation times by guiding the selection phase based on game state.
To achieve this modularity I use an environment class which can be used to query and modify game state independent of internal mechanics. Since the game is abstracted through this interface the algorithm is not bound to any particular user interface, though I have chosen the command line for simplicity in my examples.
To provide a better playing experience the algorithm is bounded by a configurable “thinking” time, after which an action is chosen. This was chosen over a fixed iteration cap to prevent game complexity from affecting user experience. Due to this, the effectiveness of the AI is a function of game complexity (time spent processing game logic) and the thinking time limit.
Application & Limitations
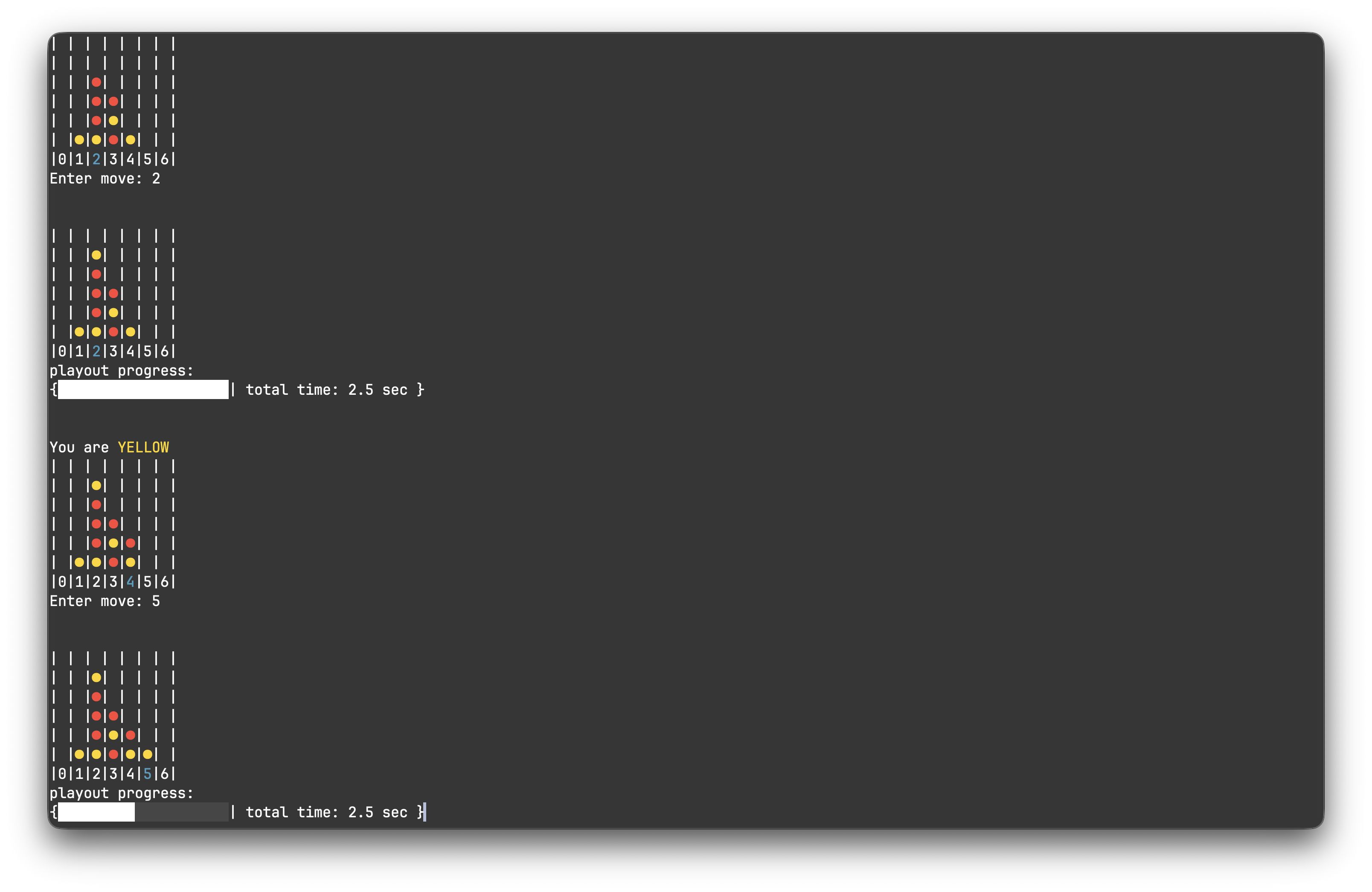
I have applied the algorithm to two simple game systems as a proof of concept: Tic-Tac-Toe and Connect Four. The AI is incredibly effective at these, and forces either a win or draw in all test games I have run.
Python was chosen for this project as it allowed for easier implementation and testing of the algorithm. While this was a good decision for my learning and exploration, Python’s interpreted nature creates performance constraints. In more complex game systems (namely checkers from my testing) the overhead of creating and running countless game environments drastically reduces the number of simulations run in a fixed time frame. This reduces the AI’s effectiveness in these positions, as it is not allowed enough exploration of the decision space. Switching over to a compiled language properly optimizing game engines would likely address this issue.