Overview
This project was completed as an open-ended final for my Intro to Machine Learning class. We were tasked with finding a use case for machine learning, applying what we learned that semester, and evaluating the results.
The purpose of this project is to determine the feasibility of using machine learning models to predict political affiliation from open-access donation data. In this case I specifically predicted which major party (democrat, republican, independent) a person was likely to donate to based on occupation, zip code, and donation size.
If successful this kind of model could be used for political campaigning & fundraising, and advertisement.
For a more detailed breakdown, see the linked report
Technical Details
Data
I sourced my data from the FEC individual contributions database, which provides legally required record of all donations made to political campaigns by individuals. I specifically used data from the 2024 presidential campaign, as it provided a large and varied data set. In order to avoid confusion in the data, I only took donation entries from after President Biden dropped out of the race. The original dataset I acquired contained ~5M contributions, which was reduced to 1.5M after pre-processing.
Interestingly this data set was heavily skewed toward democratic donors, with nearly 89% of filtered donations being to a democratic party. To try and address this, I balanced the dataset using re-sampling and bootstrapping. After this balancing the training set was reduced to 350k entries.
Features
Party (target)
Labeled as committee_name, this feature contained 18 possible donation recipients; which could be easily mapped to a major political party.
Zip Code The zip code system already groups nearby locations by numerical value, making it well-suited for training input. To keep consistency I truncated all zip-codes to their standard 5 digits.
Occupation This feature comprised of natural language input describing job title. To prep this feature I used a natural language processor to map each occupation title to the government’s Standard Occupational Classification system. This system classifies 867 job types, which are grouped numerically by similarity. This provides an excellent encoding for job titles.
Donations Both a total donation amount and current donation amount were available, I standardized each of these.
Training
I trained both kNN and Random Forest models on the processed data, experimenting with hyper-parameter tuning. I also experimented with removing donation features from the dataset.
Results
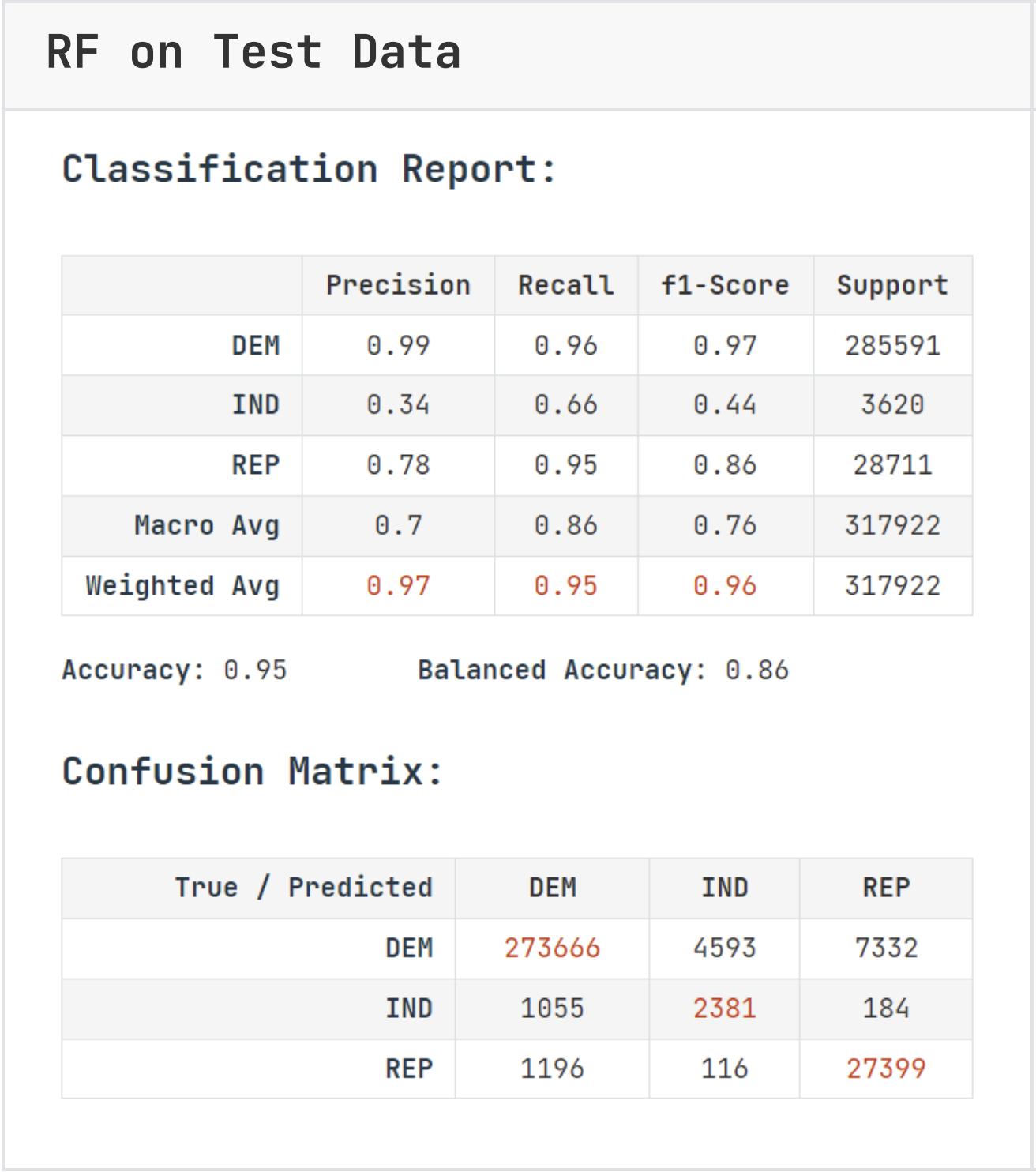
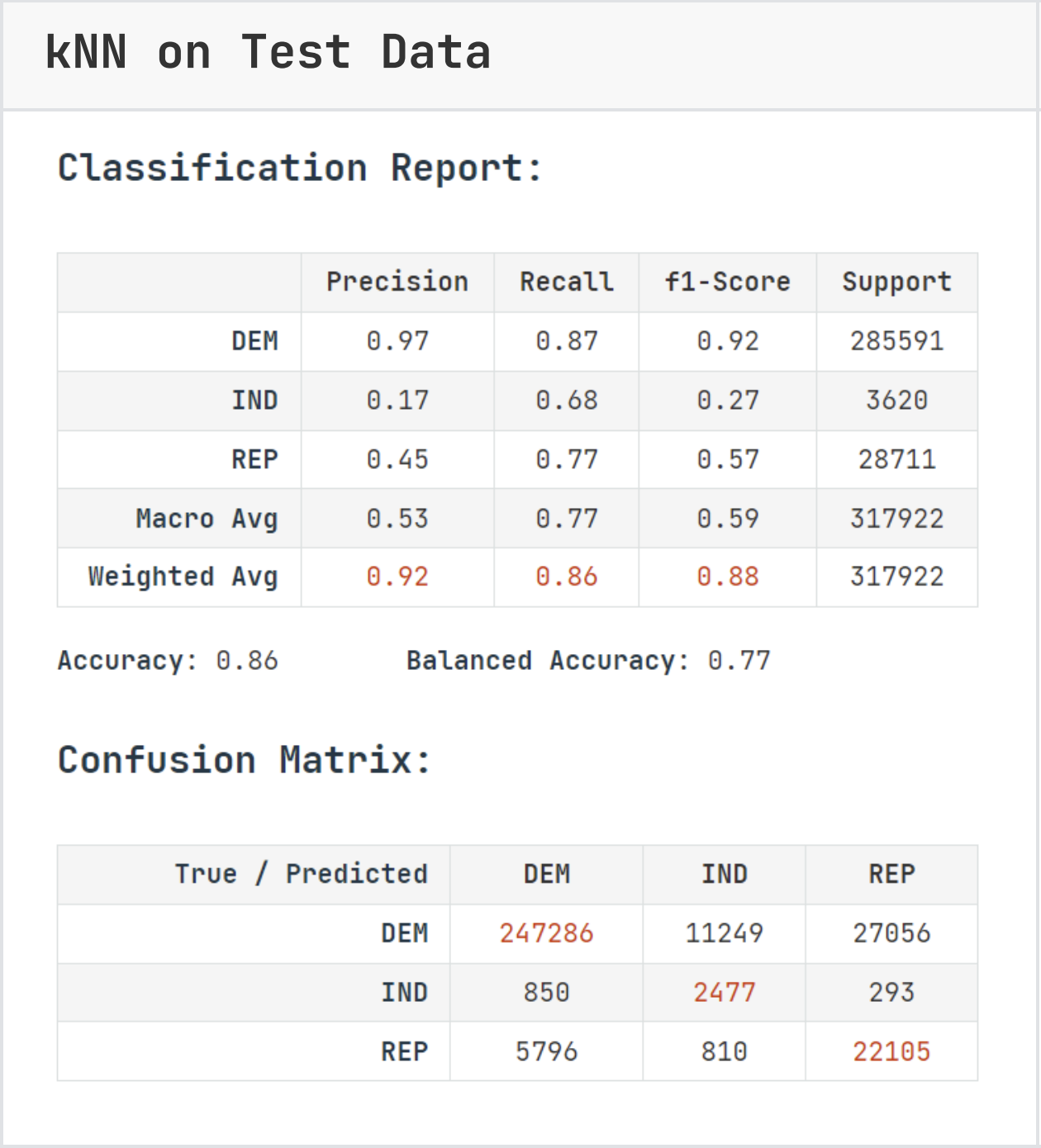
Both models performed quite well. Notably random forest is able to interpret donation data and gain on some metrics, while kNN cannot. Random Forest took significantly longer to fit and predict (79sec vs 40sec), this is due to kNN making runtime predictions instead of training. While this difference is minimal, it is worth taking the speed vs accuracy into account when scaling.
Both models performed significantly better at identifying democratic donors than the other parties due to dataset imbalance. There were far more democratic donors in the original dataset than other parties, which provided richer context even after balancing.
Conclusion
The models are effective at identifying donor tendencies, but are not ready for any kind of production use-case. In order to close this gap I would recommend gathering more data for republican and independent donations. If these categories had equal diversity to the democratic party, the model would likely gain a substantial classification improvement.